在Kubernetes上部署一套 Redis 集群 |
您所在的位置:网站首页 › k8s redis operator › 在Kubernetes上部署一套 Redis 集群 |
在Kubernetes上部署一套 Redis 集群
|
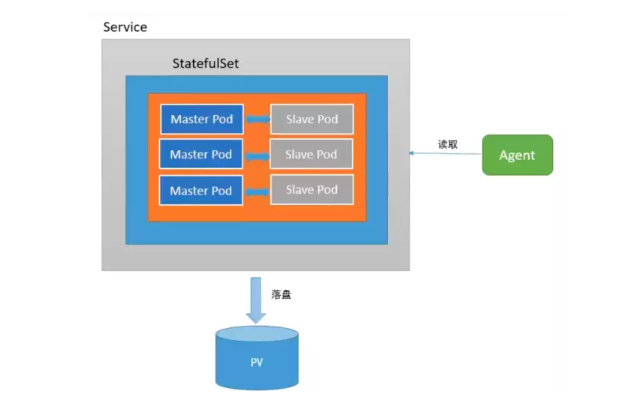
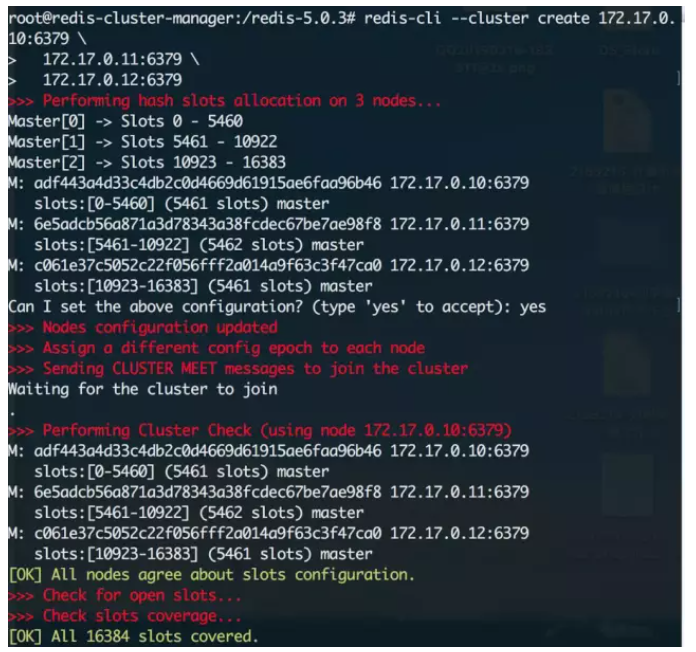
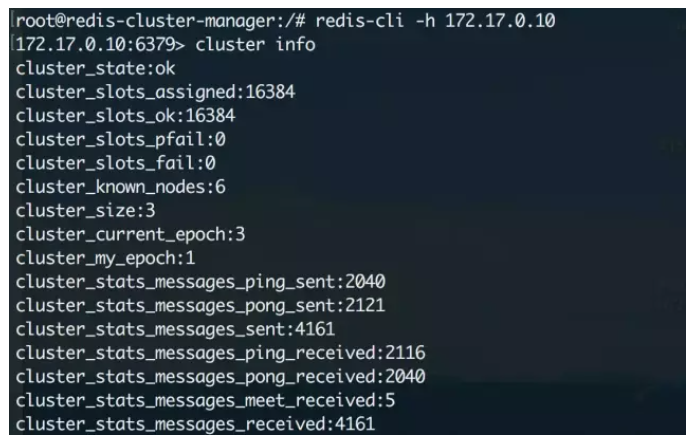
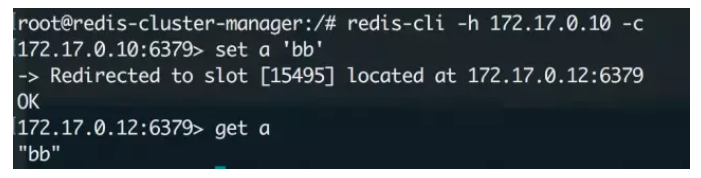
今天让我们试着在k8s里部署一个redis集群,了解更多k8s的细节和特性。 注:redis-cluster相关的背景知识和细节在此不做赘述 一、问题分析 本质上来说,在k8s上部署一个redis集群和部署一个普通应用没有什么太大的区别,但需要注意下面几个问题: Redis是一个有状态应用 这是部署redis集群时我们最需要注意的问题,当我们把redis以pod的形式部署在k8s中时,每个pod里缓存的数据都是不一样的,而且pod的IP是会随时变化,这时候如果使用普通的deployment和service来部署redis-cluster就会出现很多问题,因此需要改用StatefulSet + Headless Service来解决 数据持久化 redis虽然是基于内存的缓存,但还是需要依赖于磁盘进行数据的持久化,以便服务出现问题重启时可以恢复已经缓存的数据。在集群中,我们需要使用共享文件系统 + PV(持久卷)的方式来让整个集群中的所有pod都可以共享同一份持久化储存 二、概念介绍 在开始之前先来详细介绍一下几个概念和原理。 1、Headless Service 简单的说,Headless Service就是没有指定Cluster IP的Service,相应的,在k8s的dns映射里,Headless Service的解析结果不是一个Cluster IP,而是它所关联的所有Pod的IP列表 2、StatefulSet StatefulSet是k8s中专门用于解决有状态应用部署的一种资源,总的来说可以认为它是Deployment/RC的一个变种,它有以下几个特性: StatefulSet管理的每个Pod都有唯一的文档/网络标识,并且按照数字规律生成,而不是像Deployment中那样名称和IP都是随机的(比如StatefulSet名字为redis,那么pod名就是redis-0, redis-1 ...) StatefulSet中ReplicaSet的启停顺序是严格受控的,操作第N个pod一定要等前N-1个执行完才可以 StatefulSet中的Pod采用稳定的持久化储存,并且对应的PV不会随着Pod的删除而被销毁 另外需要说明的是,StatefulSet必须要配合Headless Service使用,它会在Headless Service提供的DNS映射上再加一层,最终形成精确到每个pod的域名映射,格式如下: $(podname).$(headless service name) 有了这个映射,就可以在配置集群时使用域名替代IP,实现有状态应用集群的管理 三、方案 借助StatefulSet和Headless Service,集群的部署方案设计如下(图片来自参考文章): 配置步骤大概罗列如下: 配置共享文件系统NFS 创建PV和PVC 创建ConfigMap 创建Headless Service 创建StatefulSet 初始化redis集群 实际操作 为了简化复杂度,这次先不配置PV和PVC,直接通过普通Volume的方式来挂载数据。 1、创建ConfigMap 先创建redis.conf配置文件 appendonly yes cluster-enabled yes cluster-config-file /var/lib/redis/nodes.conf cluster-node-timeout 5000 dir /var/lib/redis port 6379然后kubectl create configmap redis-conf --from-file=redis.conf来创建ConfigMap 2、创建HeadlessService apiVersion: v1 kind: Service metadata: name: redis-service labels: app: redis spec: ports: - name: redis-port port: 6379 clusterIP: None selector: app: redis appCluster: redis-cluster3、创建StatefulSet apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: redis-app spec: serviceName: "redis-service" replicas: 6 template: metadata: labels: app: redis appCluster: redis-cluster spec: terminationGracePeriodSeconds: 20 affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - redis topologyKey: kubernetes.io/hostname containers: - name: redis image: "registry.cn-qingdao.aliyuncs.com/gold-faas/gold-redis:1.0" command: - "redis-server" args: - "/etc/redis/redis.conf" - "--protected-mode" - "no" resources: requests: cpu: "100m" memory: "100Mi" ports: - name: redis containerPort: 6379 protocol: "TCP" - name: cluster containerPort: 16379 protocol: "TCP" volumeMounts: - name: "redis-conf" mountPath: "/etc/redis" - name: "redis-data" mountPath: "/var/lib/redis" volumes: - name: "redis-conf" configMap: name: "redis-conf" items: - key: "redis.conf" path: "redis.conf" - name: "redis-data" emptyDir: {}4、初始化redis集群 StatefulSet创建完毕后,可以看到6个pod已经启动了,但这时候整个redis集群还没有初始化,需要使用官方提供的redis-trib工具。 我们当然可以在任意一个redis节点上运行对应的工具来初始化整个集群,但这么做显然有些不太合适,我们希望每个节点的职责尽可能地单一,所以最好单独起一个pod来运行整个集群的管理工具。 在这里需要先介绍一下redis-trib,它是官方提供的redis-cluster管理工具,可以实现redis集群的创建、更新等功能,在早期的redis版本中,它是以源码包里redis-trib.rb这个ruby脚本的方式来运作的(pip上也可以拉到python版本,但我运行失败),现在(我使用的5.0.3)已经被官方集成进redis-cli中。 开始初始化集群,首先在k8s上创建一个ubuntu的pod,用来作为管理节点: kubectl run -i --tty redis-cluster-manager --image=ubuntu --restart=Never /bin/bash进入pod内部先安装一些工具,包括wget,dnsutils,然后下载和安装redis: wget http://download.redis.io/releases/redis-5.0.3.tar.gz tar -xvzf redis-5.0.3.tar.gz cd redis-5.0.3.tar.gz && make编译完毕后redis-cli会被放置在src目录下,把它放进/usr/local/bin中方便后续操作 接下来要获取已经创建好的6个节点的host ip,可以通过nslookup结合StatefulSet的域名规则来查找,举个例子,要查找redis-app-0这个pod的ip,运行如下命令: root@redis-cluster-manager:/# nslookup redis-app-0.redis-service Server: 10.96.0.10 Address: 10.96.0.10#53 Name: redis-app-0.redis-service.gold.svc.cluster.local Address: 172.17.0.10172.17.0.10就是对应的ip。这次部署我们使用0,1,2作为Master节点;3,4,5作为Slave节点,先运行下面的命令来初始化集群的Master节点: redis-cli --cluster create 172.17.0.10:6379 172.17.0.11:6379 172.17.0.12:6379然后给他们分别附加对应的Slave节点,这里的cluster-master-id在上一步创建的时候会给出: redis-cli --cluster add-node 172.17.0.13:6379 172.17.0.10:6379 --cluster-slave --cluster-master-id adf443a4d33c4db2c0d4669d61915ae6faa96b46 redis-cli --cluster add-node 172.17.0.14:6379 172.17.0.11:6379 --cluster-slave --cluster-master-id 6e5adcb56a871a3d78343a38fcdec67be7ae98f8 redis-cli --cluster add-node 172.17.0.16:6379 172.17.0.12:6379 --cluster-slave --cluster-master-id c061e37c5052c22f056fff2a014a9f63c3f47ca0集群初始化后,随意进入一个节点检查一下集群信息: 至此,集群初始化完毕,我们进入一个节点来试试,注意在集群模式下redis-cli必须加上-c参数才能够访问其他节点上的数据: 5、创建Service 现在进入redis集群中的任意一个节点都可以直接进行操作了,但是为了能够对集群其他的服务提供访问,还需要建立一个service来实现服务发现和负载均衡(注意这里的service和我们之前创建的headless service不是一个东西) yaml文件如下: apiVersion: v1 kind: Service metadata: name: gold-redis labels: app: redis spec: ports: - name: redis-port protocol: "TCP" port: 6379 targetPort: 6379 selector: app: redis appCluster: redis-cluster部署完做个测试: 很nice,到这里所有的工作就完毕了~ |

【本文地址】